
Amazon S3 Tables の Iceberg テーブルに従来のGlueテーブルでUPSERTしてみる #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。本日は、Amazon S3 Tables のIcebergテーブルにサンプルデータ「SSB」のlineorderデータ(6億レコード)のうちを1992年10月1日データのみをUPSERTする方法を紹介します。なお、データファイルは以下のブログで紹介しているファイルです。
AWS Glue でNamespaceとテーブルの作成、データ追加
以降の検証は、US East (N. Virginia) us-east-1 リージョンで実施しました。
マネジメントコンソールからテーブルバケットを作成
[Table buckets New ]のメニューを選び、[Create table bucket]を押します。
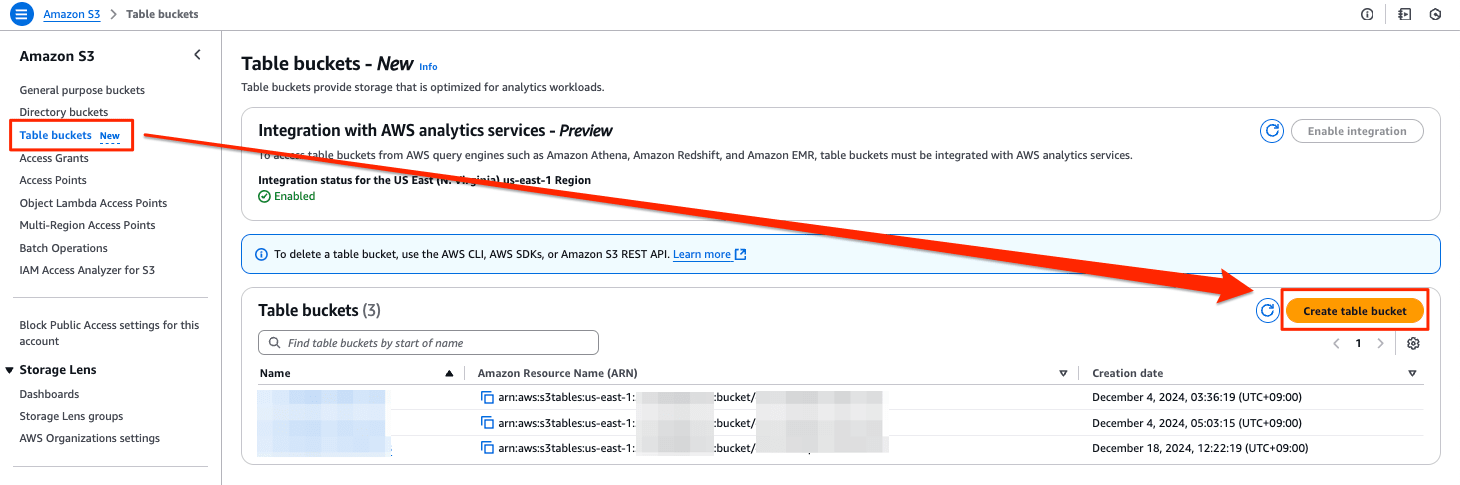
Table bucket nameを入力して、[Create table bucket]を押します。

Glue ETL ジョブの作成
S3 Tables用のランタイムのダウンロード
以下のリンクからダウンロードしてください。
s3-tables-catalog-for-iceberg-runtime-0.1.3.jar
ジョブの設定
Job details タブの各項目に以下の設定を追加してください。
- Glue version: Glue 5.0
- Worker type: G 1X
- Requested number of workers: 2
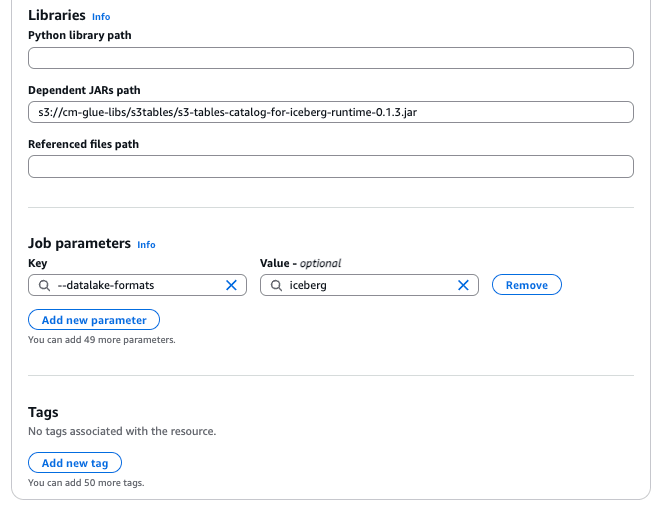
- Dependent JARs path:
s3://<your_bucket>/<your_key>/s3-tables-catalog-for-iceberg-runtime-0.1.3.jar - Job parameters:
--datalake-formatsiceberg
ソースコードの解説
従来のGlueテーブル用のglueContextやSparkSessionを作成します。グローバルスコープでこれらを利用できるようにすることは個人的には抵抗があるのですが、致し方ないです。
# sc = SparkContext()
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
S3 Tables用のSparkSessionの作成を関数にしています。SparkSessionは、Sparkアプリケーションのプライマリエントリーポイントであるため、getOrCreate()でインスタンスを取得しています。
def build_spark_session_s3t(namespace, warehouse_arn):
spark = SparkSession.builder \
.config(f"spark.sql.catalog.{namespace}", "org.apache.iceberg.spark.SparkCatalog") \
.config(f"spark.sql.catalog.{namespace}.warehouse", warehouse_arn) \
.config(f"spark.sql.catalog.{namespace}.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.getOrCreate()
return(spark)
従来のGlueテーブルからDynamicFrameを作成します。その際にpush_down_predicateというフィルタ条件を追加することで必要なレコードのみを読み込み(インスタンス化)します。最終的にはSparkSQLで利用するため、ここでDataframeに変換しています。
TARGET_DATE = '1992-10-01'
# Create Spark Session for S3 Tables
warehouse_arn = "arn:aws:s3tables:us-east-1:517444948157:bucket/cm-namespace-20241222"
spark_s3t = build_spark_session_s3t("s3tablesbucket", warehouse_arn)
# Dynamic Frame from catalog
partition_predicate = f"lo_orderdate='{TARGET_DATE}'"
lineorder_p = glueContext.create_dynamic_frame.from_catalog(
database="ssb",
table_name="lineorder_p",
push_down_predicate = partition_predicate,
transformation_ctx="lineorder_p",
)
df = lineorder_p.toDF()
df.printSchema()
df.show()
print(df.count())
S3 Tables のテーブル(ターゲットテーブル)であるlineorderから既存の日付のレコードを削除した後、上記で読み込んだレコードを追加します。
# Delete in S3 Tables
spark_s3t.sql(f""" DELETE FROM s3tablesbucket.cm_namespace.`lineorder` WHERE lo_orderdate = '{TARGET_DATE}' """)
# Use Namespace
spark_s3t.sql(""" USE s3tablesbucket.cm_namespace """)
# Show Tables
spark_s3t.sql(""" SHOW TABLES """).show()
# Insert records into Iceberg table in S3 Tables
df.createOrReplaceTempView("tmp_lineorder")
spark_s3t.sql(f"""
INSERT INTO s3tablesbucket.cm_namespace.`lineorder`
SELECT * FROM tmp_lineorder WHERE lo_orderdate = '{TARGET_DATE}'
""")
# Read from Iceberg table in S3 Tables
df_out=spark_s3t.sql(""" SELECT * FROM s3tablesbucket.cm_namespace.`lineorder` """)
df_out.show()
print(df_out.count())
なお、今回の検証では、S3 Tables のテーブルにIcebergのパーティション指定を試してみました。テーブルは全く問題なくテーブルは作成できていますが、Amazon Athenaの画面では、「partitioned」という表示はなく確認するすべはありません。また、Amazon Athenaの画面からDDLの取得を試みましたが「DDL queries are not supported for this catalog」というメッセージが出てエラーになりました。
ソースコード(全体)
Scriptタブに以下のコードをコピーします。warehouseには、作成したS3 Tablesのarnに変更してください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.conf import SparkConf
from awsglue.job import Job
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# sc = SparkContext()
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
def build_spark_session_s3t(namespace, warehouse_arn):
spark = SparkSession.builder \
.config(f"spark.sql.catalog.{namespace}", "org.apache.iceberg.spark.SparkCatalog") \
.config(f"spark.sql.catalog.{namespace}.warehouse", warehouse_arn) \
.config(f"spark.sql.catalog.{namespace}.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.getOrCreate()
return(spark)
TARGET_DATE = '1992-10-01'
# Create Spark Session for S3 Tables
warehouse_arn = "arn:aws:s3tables:us-east-1:123456789012:bucket/cm-namespace-20241222"
spark_s3t = build_spark_session_s3t("s3tablesbucket", warehouse_arn)
# Dynamic Frame from catalog
partition_predicate = f"lo_orderdate='{TARGET_DATE}'"
lineorder_p = glueContext.create_dynamic_frame.from_catalog(
database="ssb",
table_name="lineorder_p",
push_down_predicate = partition_predicate,
transformation_ctx="lineorder_p",
)
df = lineorder_p.toDF()
df.printSchema()
df.show()
print(df.count())
# # Create namespace in S3 Tables
# spark_s3t.sql(""" CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.cm_namespace """)
# # DROP Table using Iceberg in S3 Tables
# spark_s3t.sql("""
# DROP TABLE IF EXISTS s3tablesbucket.cm_namespace.`lineorder` PURGE
# """)
# # Create Table using Iceberg in S3 Tables
# spark_s3t.sql("""
# CREATE TABLE IF NOT EXISTS s3tablesbucket.cm_namespace.`lineorder` (
# `lo_orderkey` int,
# `lo_linenumber` int,
# `lo_custkey` int,
# `lo_partkey` int,
# `lo_suppkey` int,
# `lo_orderpriority` string,
# `lo_shippriority` string,
# `lo_quantity` int,
# `lo_extendedprice` int,
# `lo_ordertotalprice` int,
# `lo_discount` int,
# `lo_revenue` int,
# `lo_supplycost` int,
# `lo_tax` int,
# `lo_commitdate` string,
# `lo_shipmode` string,
# `lo_orderdate` string
# ) USING iceberg
# PARTITIONED BY (`lo_orderdate`)
# """)
# Delete in S3 Tables
spark_s3t.sql(f""" DELETE FROM s3tablesbucket.cm_namespace.`lineorder` WHERE lo_orderdate = '{TARGET_DATE}' """)
# Use Namespace
spark_s3t.sql(""" USE s3tablesbucket.cm_namespace """)
# Show Tables
spark_s3t.sql(""" SHOW TABLES """).show()
# Insert records into Iceberg table in S3 Tables
df.createOrReplaceTempView("tmp_lineorder")
spark_s3t.sql(f"""
INSERT INTO s3tablesbucket.cm_namespace.`lineorder`
SELECT * FROM tmp_lineorder WHERE lo_orderdate = '{TARGET_DATE}'
""")
# Read from Iceberg table in S3 Tables
df_out=spark_s3t.sql(""" SELECT * FROM s3tablesbucket.cm_namespace.`lineorder` """)
df_out.show()
print(df_out.count())
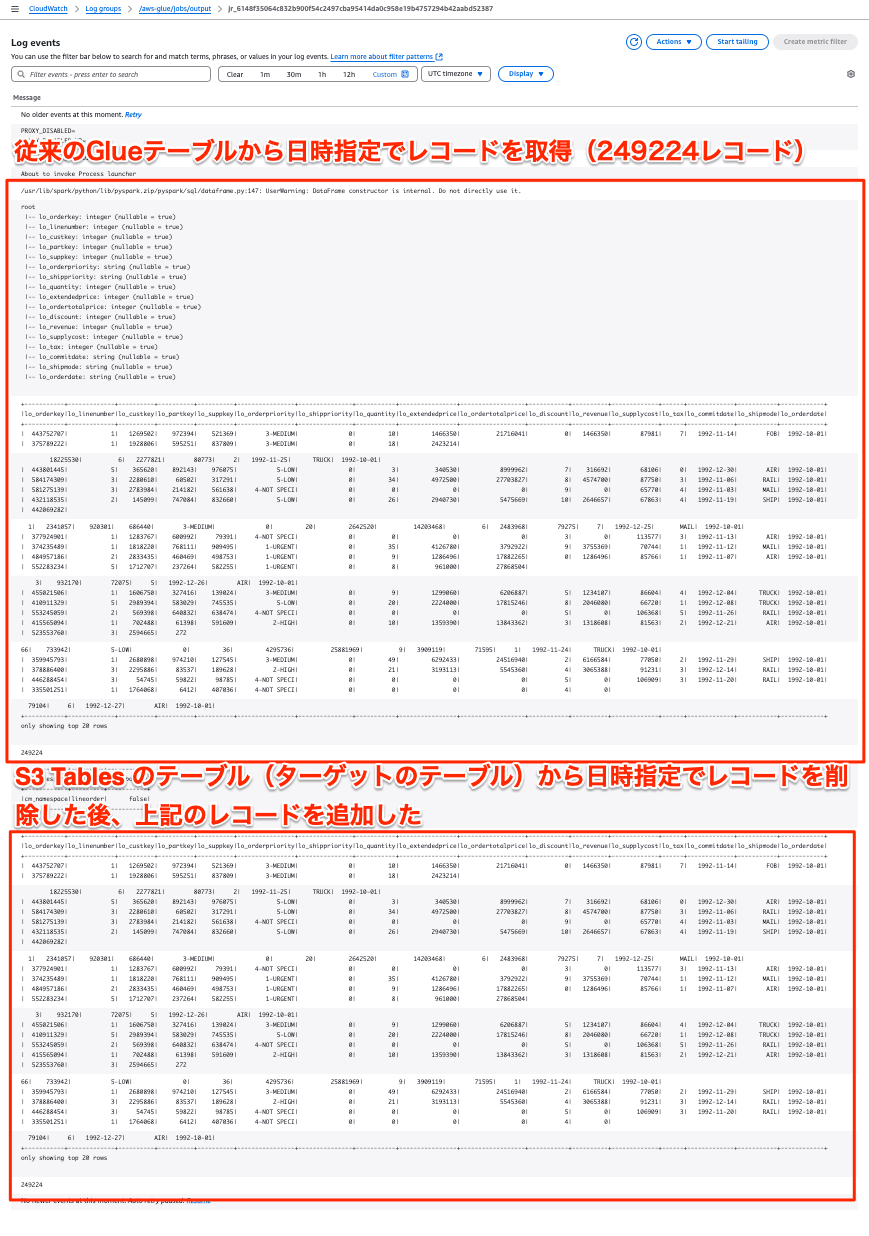
実行結果
上記のGlue ETLジョブを実行したログファイルです。上が従来のGlueテーブルのlineorderデータ(6億レコード)のうちを1992年10月1日データのみをDataframe読み込み、表示した結果です。一方、下がそのレコードでUPSERTしたS3 Tables のテーブル(lineorder)のレコードの結果表示です。
Amazon Athenaのクエリエディタで確認します。レコードが追加されていることが確認できます。
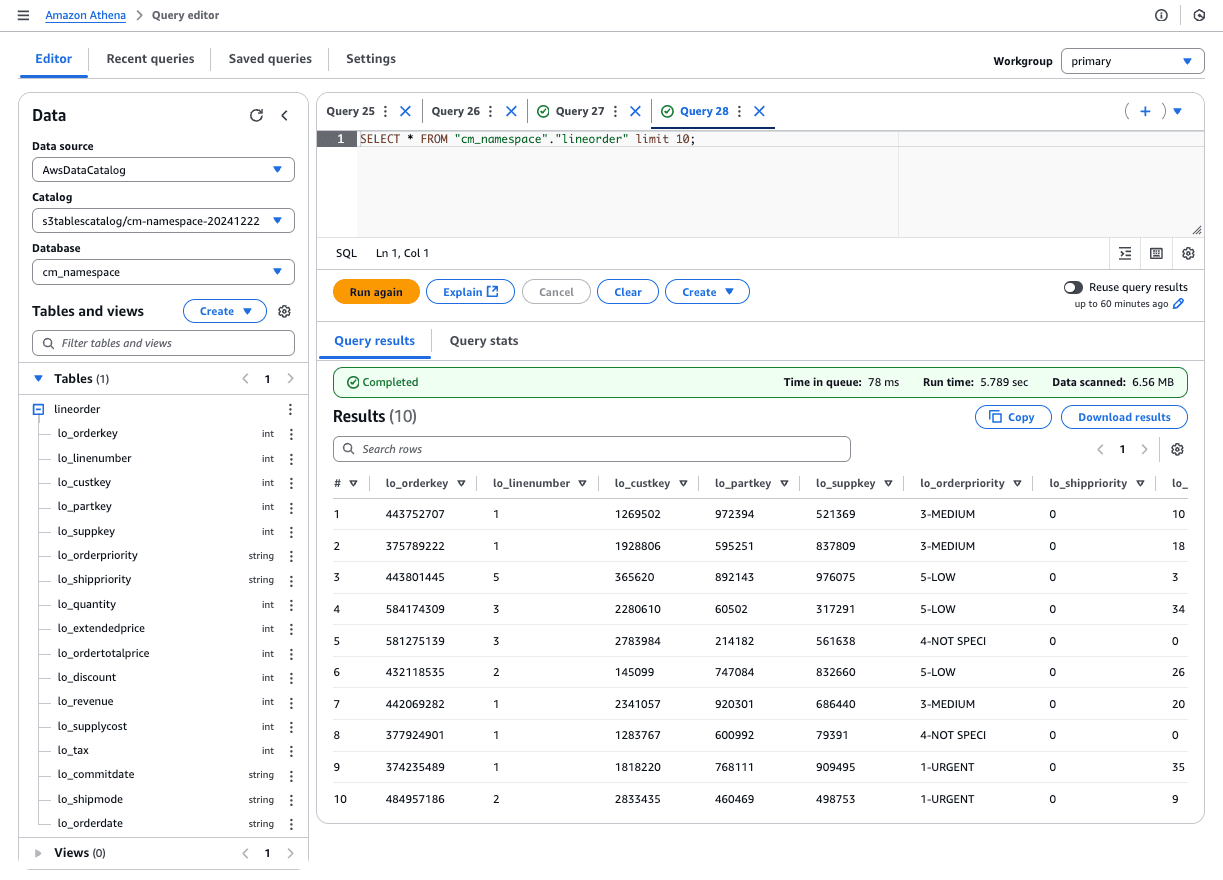
何度実行しても冪等性を確保しており、レコード数も1992年10月1日データのみが入っていることが確認できます。
最後に
Amazon S3 TablesとAWS Glueを組み合わせることで、大規模なデータセットを効率的に処理し、Icebergフォーマットのテーブルに取り込む方法を紹介しました。AWS Glue ETLジョブを活用することで、データのUPSERT操作やパーティション単位での処理が可能となり、柔軟なデータ管理を実現します。
さらに、Amazon Athenaとの連携により、メタデータのみを使用した高速なクエリ実行が可能となり、コスト効率の高いデータ分析環境を構築できます。この方法は、実務での活用を見据えた実践的なアプローチであり、今後のビッグデータ処理や分析基盤の構築に大きな可能性を示しています。
ただし、S3 Tables用のSpark Session作成やベストプラクティスについては、さらなる検証と最適化の余地があり、今後の課題として残されています。









